{kind=link}
前回までの投稿では、「画像検索の精度確認」と銘打って、特にワインの画像から商品を特定する方法に関して試行錯誤してきました。
その結果は、残念ながら「不十分」と言わざるを得ないものでした。
まずはボトル全体を写した画像からチャレンジしましたが、エンベディング時の対象画像サイズが224×224と小さめであるため、当該商品の特徴を十分にベクトルに反映し切れない模様で、同じ商品を同じ、違う商品を違う、と的確に判断できるようなベクトル群を生成できませんでした。
次に、商品の特徴(差異)が最も顕著に反映されているラベル(エチケット)のみを写した画像で試そうとしましたが、背景の除去およびラベル部分のみのトリミングがボトル全体で採用した方法(rembgによる背景除去およびfindContours等を用いた輪郭検出)では困難で、エンベディングに有効な画像を用意できませんでした。
ワインの判別にラベルを用いる方針に関しては同様の機能を持つ既存ソフトなどでも採用されているものであり、多分正解であると思われます。
よって、やはりこの点をなんとかするしかなさそうです。
ということで、改めて写真の中からワインのラベル部分のみを抽出する方法に集中して調査を進めたいと思います。
セマンティックセグメンテーション
困った時はとりあえずGemini先生のご託宣をいただくことにしていますが、幾つか提示された方法の中で、かろうじて手が出せそうな内容が「セマンティックセグメンテーション」でした。
「セマンティックセグメンテーション」が何であるかに関してもGemini先生に解説していただきましょう。
セマンティックセグメンテーション(Semantic Segmentation)は、画像認識技術の一つで、画像内の各ピクセルに対して、それがどのクラス(意味)に属するかを識別し、分類する技術です。
例えば、画像内の「空」「道路」「人」「車」などの領域をピクセル単位で正確に区別します。つまり、今回の目的に照らして言えば、ワインのラベルが写された画像に関して、同画像内の全てのピクセルをラベルとそれ以外の2つのクラスに分類すると言うことになります。
上記解説では明言されていませんが、当然ながらAI(ディープラーニング)を使用することになります。
この段階で、かなり先行き不安ですが…
アノテーション
ラベル部分を識別するAIモデルを生成するためには学習データが必要になりますが、具体的には、ラベルを写した画像データと、その画像のどの部分がラベルに該当するかを示す情報が必要です。
後者のデータを生成する作業を「アノテーション」と呼ぶようです。
以下、「アノテーション」に関するGemini先生の解説です。
セマンティックセグメンテーションにおけるアノテーション(annotation)とは、画像内の各ピクセルに対して、それがどのクラス(意味)に属するかを示すラベルを付与する作業のことです。
セマンティックセグメンテーションのモデルは、大量の教師データを用いて学習されます。
アノテーションは、教師データとなる画像に対して、正解となるクラス情報を付与する作業です。まずは、この「アノテーション」を実施してみましょう。
LabelMe
既存画像からラベル部分のみを抽出し、データ化する方法は色々とあるようですが、Gemini先生お薦めの方法は「LabelMe」なるツールを使用する方法でした。
LabelMeに関しても解説してもらいましょう。
LabelMeは、MITによって開発された画像アノテーションのためのオープンソースツールです。特に、セマンティックセグメンテーションや物体検出の学習データを作成する際に役立ちます。
アノテーション結果は、JSON形式で出力されます。JSON形式は、多くの機械学習フレームワークで利用できるため、データの互換性が高いです。なかなか良さそうです。
LabelMeのインストール自体はPython環境で簡単に行えるようです。
# pip install labelme PyQt5PyQt5は、PythonでGUIアプリケーションを開発するためのライブラリらしく、LabelMeがGUIを持つアプリケーションであるために必須とのこと。
LabelMeの画面構成や操作方法に関してはネット上にも情報があるので詳しく触れませんが、大まかには以下のような手順でアノテーション結果(JSON)を生成します。
- 「Open」をクリックすると、対象ファイル(JPG等)が選択できるダイアログが表示されるので、目的とするファイルを選択。
- 「Edit」メニューから「Create AI-Polygon」を選択。
画像内のラベル上の適当な位置でクリックするとラベルを囲むようにPolygon(多角形)が自動生成される(対象画像によってラベル部分の認識精度には差がありますが、後から修正できるので、それっぽい範囲が選択できていれば良いです)。
上記状態で再度Polygon上でダブルクリックすると、当該Polygonに対して命名するためのダイアログが表示されるので、適当な名前をつける(今回はetiquetteとしました)。 - 「Edit Polygons」をクリックすると先に生成したPolygonの編集ができるようになるので、Polygonを形成するポイントの位置を移動させたり、不要なポイントを削除したりする。
- 「Save」をクリックするとJSONファイルを保存するためのダイアログが表示される。
デフォルトの名称は対象画像ファイル名の拡張子が「.json」に変更されたものになるので、このまま保存を実行。
アノテーション結果(JSON)の内容
アノテーション結果の確認方法として、最も簡単なのはLabelMeに付属する「labelme_draw_json」コマンドを使用する方法です。
引数として生成したJSONファイルを指定すると、元画像とアノテーション結果を並べて表示してくれます。
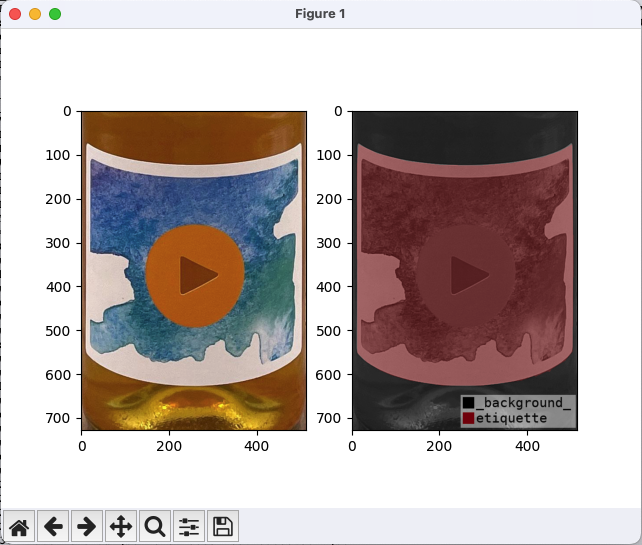
上記の右側の画像がアノテーション結果で、ラベルの部分(etiquette)が他の部分(_background_)と色分けして表示されています。
なお、JSONの中身は以下のような構造になっています。
{
"version": "5.8.0",
"flags": {},
"shapes": [
{
"label": "etiquette",
"points": [
[
292.0,
627.5
],
[
202.0,
626.5
],
...
[
385.0,
615.5
]
],
"group_id": null,
"description": "",
"shape_type": "polygon",
"flags": {},
"mask": null
}
],
"imagePath": "0101133654_63b10de60b5c4.jpg",
"imageData": "/9j/4AAQSk ... ooopjP/9k=",
"imageHeight": 728,
"imageWidth": 514
}「points」の内容がPolygonを構成する各ポイントの座標のようです。
「imageData」には元画像をBase64エンコード化したデータが格納されるため、ファイルが相応に大きくなります。
この元画像データは格納しないようにできるらしいので、今後の用途も見極めた上で不要そうであれば、格納しない設定も考えたいと思います。
アノテーション結果の画像化
先に示した「labelme_draw_json」のアウトプットではラベル(etiquette)として認識されている範囲が今ひとつ確認しづらいため、アノテーション結果を自力で画像化してみたいと思います。
処理は例によってPythonで記述します(当然のようにGemini先生任せです)。
まず、JSONファイルを読み込んで、Polygonの中を白、外を黒に色分けした画像データを生成する処理を作成します。
import json
import numpy as np
from PIL import Image, ImageDraw
def create_mask_from_json(json_path, image_size):
with open(json_path, 'r') as f:
data = json.load(f)
mask = Image.new('L', image_size, 0) # 白黒画像としてマスクを作成
draw = ImageDraw.Draw(mask)
for shape in data['shapes']:
points = shape['points']
points = [(int(x), int(y)) for x, y in shape['points']]
draw.polygon(points, fill=255) # ポリゴンを塗りつぶす
return np.array(mask) / 255.0 # 0-1の範囲に正規化次に、上記結果をファイルに保存する処理を作成します。
import numpy as np
from PIL import Image, ImageDraw
def save_mask_image_pil(mask_array, save_path):
mask_image = Image.fromarray((mask_array * 255).astype(np.uint8), mode='L')
mask_image.save(save_path)最後に、対象ファイル(JSON)に対して上記を実行する処理を作成します。
from create_mask_from_json import create_mask_from_json
from save_mask_image_pil import save_mask_image_pil
data_path = './label_mask/'
json_file = '0101133654_63b10de60b5c4.json'
image_size = (514, 728) # マスク画像のサイズ
save_file = json_file.replace('.json', '.png') # 保存先のファイルパス
mask_array = create_mask_from_json(data_path + json_file, image_size)
save_mask_image_pil(mask_array, data_path + save_file)結果は以下の通り。


ラベル部分のみ白く塗りつぶされていることが良く分かります。
まとめ
今回から「ラベル画像のトリミング」と銘打って、セマンティックセグメンテーションによるラベル部分の認識と、その結果を利用してラベル部分のみを別画像として抽出する方法を、何回かに分けて模索していきたいと思っています。
その第一弾として、アノテーションまでを実施してみました。
上記過程で最終的に生成したラベル部分のマスク画像を元画像から自動的に生成できるのであれば、ラベル以外の部分を黒く塗りつぶした上で、不要な部分を極力除外した224×224の画像が生成できるようになります。
上記は、元画像の中でラベルがどの位置にどの程度の大きさで写っているかという画像ごとの差異を極力排除し、224×224の範囲に無駄なく収まるラベル画像が生成できると言うことであり、これは同じラベルを撮影した複数の画像に対して、少なくともレイアウト的には極めて類似性の高い画像への加工が実現できるということであるため、その後のエンベディングの結果においても、生成された特徴ベクトルの散らばり(元画像ごとのベクトルの差異)を小さくする効果が期待できます。
結局はセマンティックセグメンテーションを実現するAIモデルの精度が重要であり、そこが一番難しいところなので、この先どうなるか分かりませんが、まずはこの方向性で作業を進めていきたいと思います。